دیر یا زود ، هر کسی که اغلب با برنامه های اداری کار می کند ، با یک کار معمولی روبرو است - اسکن کردن متن از یک کتاب ، مجله ، روزنامه ، به سادگی جزوه ها ، و سپس ترجمه این تصاویر به فرمت متن ، به عنوان مثال ، در یک سند Word.
برای این کار به یک اسکنر و یک برنامه ویژه برای تشخیص متن نیاز دارید. در این مقاله درباره همتای رایگان FineReader بحث خواهد شد -خط میخی (در مورد شناخت در FineReader - به این مقاله مراجعه کنید).
بیایید شروع کنیم ...
مطالب
- 1. ویژگی های برنامه CuneiForm ، ویژگی ها
- 2. نمونه شناخت متن
- 3. تشخیص متن دسته ای
- 4. نتیجه گیری
1. ویژگی های برنامه CuneiForm ، ویژگی ها
 خط میخی
خط میخی
می توانید آن را از سایت توسعه دهنده بارگیری کنید: //cognitiveforms.com/
یک برنامه تشخیص متن منبع باز. علاوه بر این ، در تمام نسخه های ویندوز کار می کند: XP ، Vista ، 7 ، 8 ، که خوشحال است. به علاوه ، ترجمه کامل روسی از برنامه را اضافه کنید!
جوانب مثبت:
- تشخیص متن در 20 زبان محبوب جهان (انگلیسی و روسی به خودی خود در این شماره گنجانده شده است).
- پشتیبانی گسترده برای فونت های مختلف چاپ.
- فرهنگ لغت متن شناخته شده را بررسی کنید.
- امکان صرفه جویی در نتایج کار از چندین طریق
- حفظ ساختار سند؛
- پشتیبانی عالی و تشخیص جدول.
منفی:
- از اسناد و پرونده های خیلی بزرگ پشتیبانی نمی کند (بیش از 400 dpi).
- به طور مستقیم از انواع خاصی از اسکنر پشتیبانی نمی کند (خوب ، این یک کار بزرگ نیست ، یک برنامه اسکنر ویژه با درایور اسکنر گنجانده شده است).
- طراحی نمی درخشد (اما اگر برنامه به طور کامل مشکل را حل کند چه کسی به آن نیاز دارد).
2. نمونه شناخت متن
فرض می کنیم که شما قبلاً تصاویر لازم را برای شناخت دریافت کرده اید (در آنجا اسکن شده اید ، یا کتابی را با فرمت pdf / djvu در اینترنت بارگیری کرده اید و تصاویر لازم را از آنها حذف کرده اید. چگونه این کار را انجام دهید ، به این مقاله مراجعه کنید).
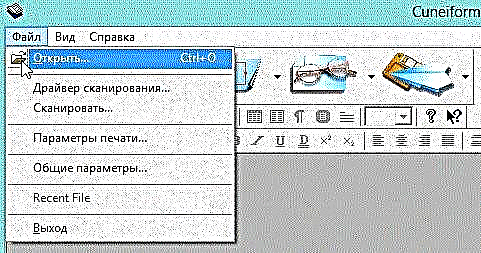
1) تصویر مورد نظر را در برنامه CuineForm (پرونده / باز یا "Cntrl + O") باز کنید.
2) برای شروع به رسمیت شناختن - ابتدا باید مناطق مختلفی را انتخاب کنید: متن ، تصاویر ، جداول و غیره در برنامه Cuneiform ، این کار نه تنها به صورت دستی ، بلکه امکان پذیر است به طور خودکار! برای انجام این کار ، بر روی دکمه "طرح" در قسمت بالای پنجره کلیک کنید.

3) بعد از 10-10 ثانیه. این برنامه به طور خودکار تمام مناطق با رنگ های مختلف را برجسته می کند. به عنوان مثال ، یک قسمت متن به رنگ آبی برجسته می شود. به هر حال ، او همه مناطق را به درستی و نسبتاً سریع برجسته کرد. راستش ، من انتظار چنین واکنشی سریع و درست از او را نداشتم ...

4) برای کسانی که به طرح اتوماتیک اعتماد ندارند می توانید از دفترچه راهنما استفاده کنید. برای انجام این کار ، نوار ابزار وجود دارد (تصویر زیر را ببینید) که به لطف آن می توانید انتخاب کنید: متن ، جدول ، تصویر. تصویر اولیه را حرکت داده ، بزرگ و کاهش دهید ، لبه ها را برش دهید. به طور کلی ، مجموعه خوبی است.

5) بعد از اینکه همه مناطق مشخص شده اند ، می توانیم به کار خود ادامه دهیم شناخت. برای انجام این کار ، کافیست همانطور که در تصویر زیر است ، روی دکمه با همین نام کلیک کنید.

6) به معنای واقعی کلمه در 10-20 ثانیه. سندی را در Microsoft Word با متن شناخته شده مشاهده خواهید کرد. جالب اینکه در متن برای این مثال ، البته ، خطاهایی وجود داشته است ، اما تعداد بسیار کمی از آنها وجود دارد! علاوه بر این ، با توجه به کیفیت بی کیفیت مواد منبع - تصویر.
سرعت و کیفیت کاملاً قابل مقایسه با FineReader است!

3. تشخیص متن دسته ای
این عملکرد برنامه وقتی مفید باشد که نیاز به تشخیص یک تصویر نداشته باشید ، بلکه چندین بطور همزمان وجود دارد. میانبر برای شروع تشخیص دسته معمولاً در فهرست شروع پنهان است.
1) بعد از باز کردن برنامه ، می توانید یک بسته جدید ایجاد کنید ، یا بسته قبلی را که قبلاً ذخیره شده بود باز کنید. در مثال ما ، یک مورد جدید ایجاد کنید.

2) در مرحله بعد ما نام آن را می گذاریم ، ترجیحاً كسی كه شش ماه بعد آنچه را در آن ذخیره می شود به یاد بیاورد.

3) بعد ، زبان سند (روسی-انگلیسی) را انتخاب کنید ، مشخص کنید که آیا تصاویر و جداول در مواد اسکن شده شما وجود دارد یا خیر.

4) اکنون باید پوشه ای را که پرونده های شناسایی در آن قرار دارد ، مشخص کنید. به هر حال ، آنچه جالب است ، خود برنامه تمام تصاویر و سایر فایلهای گرافیکی را پیدا می کند که بتواند آنها را بشناسد و آنها را به پروژه اضافه کند. شما فقط باید موارد اضافی را حذف کنید.

5) مرحله بعدی مهم نیست - پس از شناسایی ، چه کاری را با پرونده های منبع انجام دهید. توصیه می کنم کادر انتخاب "کاری نکنید" را انتخاب کنید.

6) فقط انتخاب فرمی که در آن سند شناخته شده ذخیره می شود ، انتخاب می شود. چندین گزینه وجود دارد:
- RTF - پرونده ای از یک سند کلمه ، توسط همه دفاتر محبوب (از جمله دفاتر رایگان ، پیوند به برنامه ها) باز شده.
- txt - قالب متن ، شما فقط می توانید متن را در آن ذخیره کنید ، تصاویر و جداول نمی توانند باشند.
- htm - اگر صفحه ای را جستجو می کنید و می شناسید ، یک صفحه hypertext مناسب است. ما آن را در مثال خود انتخاب خواهیم کرد.

7) پس از کلیک بر روی دکمه "پایان" ، روند پردازش پروژه شما آغاز می شود.

8) این برنامه بسیار سریع کار می کند. پس از تشخیص ، یک برگه با پرونده های htm در مقابل شما ظاهر می شود. اگر روی چنین فایلی کلیک کنید ، یک مرورگر شروع می شود ، جایی که می توانید نتایج را مشاهده کنید. به هر حال ، بسته کار را می توان برای کار بیشتر با آن ذخیره کرد.

9) همانطور که می بینید ، نتایج کار بسیار چشمگیر است این برنامه به راحتی تصویر را تشخیص داد و در زیر آن متن به راحتی تشخیص داده شد. علیرغم اینکه برنامه رایگان است ، اما به طور کلی فوق العاده است!


4. نتیجه گیری
اگر اغلب اسناد را اسکن و تشخیص نمی دهید ، پس خرید برنامه FineReader احتمالاً معنی ندارد. اکثر کارها توسط CuneiForm به راحتی انجام می شود.
از طرف دیگر ، او همچنین معایبی دارد.
اولا ، ابزارهای بسیار کمی برای ویرایش و بررسی نتیجه وجود دارد. ثانیاً ، هنگامی که مجبورید تصاویر زیادی را تشخیص دهید ، در FineReader راحت تر است که فوراً همه چیز اضافه شده به پروژه را در ستون سمت راست مشاهده کنید: به سرعت موارد غیر ضروری را برداشته ، اصلاحات را انجام دهید ، و سوم ، CuneiForm بعنوان تشخیص در اسناد از دست می دهد: من باید سند را به ذهن بسپارم - خطاها را ویرایش کنم ، علائم نگارشی ، علامت نقل قول و غیره را قرار دهم.
این همه آیا شما هیچ برنامه ارزشمند دیگری برای تشخیص متن دارید؟